Drug target discovery is a critical early step in developing new treatments for patients. Genetic and functional genomics data generated over the past decades can enable target discovery for new drugs; research has shown that genetic evidence is highly valuable in identifying drug targets and derisking drug development at later stages [1], [2]. Therefore, incorporating diverse and genetic data sources into the drug discovery process is crucial.
Incorporation of genetic data needs well-annotated datasets. Although much information is present in the public domain, data is also available from third parties such as QIAGEN, who have curated the QIAGEN OmicSoft datasets in a consistent and detailed manner to facilitate utilization. In this use-case article, we integrate both public and curated QIAGEN OmicSoft data to build a comprehensive evidence base to identify new cancer drug targets.
Open Targets Platform: Where Data Meets Discovery
The Open Targets Consortium is a public–private partnership, currently consisting of the European Bioinformatics Institute (EBI), the Welcome-Sanger Institute, Genentech, GSK, MSD, Sanofi, and Pfizer. Founded in 2014, it bridges genetics, genomics, and drug-target discovery. Over the years, the consortium has built an open-source platform that integrates open datasets from large-scale human genetics and functional genomics domains. The data and code are fully open access under Creative Commons CC0 1.0 Public Domain Dedication and Apache License v2.0.
Including Custom Data
The Open Targets Platform (OTP) integrates a large number of public data sources. Although the platform is centqiaered around public data, other datasets can be processed, combined, and integrated with public data into OTP so that the entire knowledge base can be traversed using the Platform’s intuitive user interface. To illustrate the power of this approach, we collaborated with QIAGEN to integrate their curated OmicSoft data.
We added datasets ‘Clinical Proteomic Tumour’, ‘ENCODE’, ‘TCGA’ and ‘OncoHuman’ and investigated how they enhance the drug target ranking in OTP. Furthermore, we incorporated the BLuePrint dataset as a section in the target page. The datasets were pre-processed and added as separate data sources (see Figure 2). While OTP already includes oncology-oriented datasets, these additional datasets increase the proportion of oncology data, enabling the prioritization of previously unrecognized drug targets for cancer.
QIAGEN OmicSoft Data
QIAGEN has curated disparate datasets from thousands of studies into explorable, comparable data with enhanced curation, used in many stages of drug development. This results in a unified picture of biomarkers, disease signatures, and over 1,500 clinical measures, including tissue, treatment, and demographics.
Gentropy Pipeline
The Open Targets Consortium developed Gentropy to integrate genome-wide association study (GWAS) summary data and map polymorphisms to genes. This pipeline links genetic variability to genes and phenotypes or diseases, enabling systematic target prioritization.
The Open Targets Consortium developed Gentropy to integrate genome-wide association study (GWAS) summary data and map polymorphisms to genes. This pipeline links genetic variability to genes and phenotypes or diseases, enabling systematic target prioritization.
Many types of custom data can be integrated into Open Targets. Connecting to existing datasets are enabled by Ensembl gene IDs (ENSG) and the EMBL-EBI Experimental Factor Ontology (EFO), which maps diseases or phenotypes.
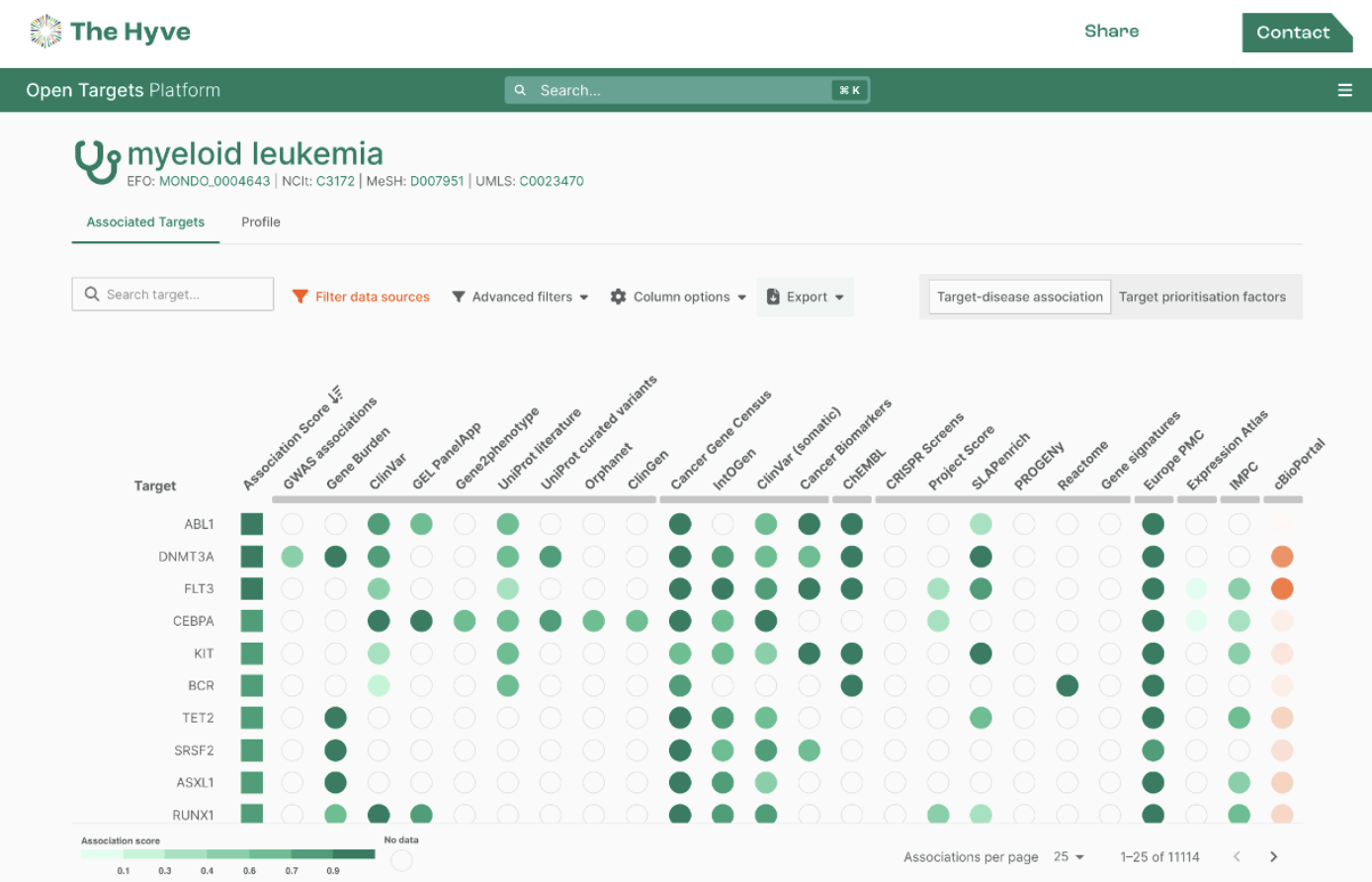
Use Case: Myeloid Leukemia
To assess the impact of adding these extra oncology-oriented datasets, we examined myeloid leukemia as an example disease to identify genes typically highlighted as potential drug targets. These include well-known cancer genes such as ABL1, FLT3, C/EBP-alpha, and KIT (Figure 1). When we supplemented the public data with OmicSoft datasets, other genes were prioritized in the top hits. One of these, SERPINA1, was prioritized mostly based on the new data (Figure 3).
Myeloid Leukemia
A clonal proliferation of myeloid cells and their precursors in the bone marrow, peripheral blood, and spleen. When the proliferating cells are immature myeloid cells and myeloblasts, it is called acute myeloid leukemia. When the proliferating myeloid cells are neutrophils, it is called chronic myelogenous leukemia. (Source: Open Targets Platform).
A clonal proliferation of myeloid cells and their precursors in the bone marrow, peripheral blood, and spleen. When the proliferating cells are immature myeloid cells and myeloblasts, it is called acute myeloid leukemia. When the proliferating myeloid cells are neutrophils, it is called chronic myelogenous leukemia. (Source: Open Targets Platform).

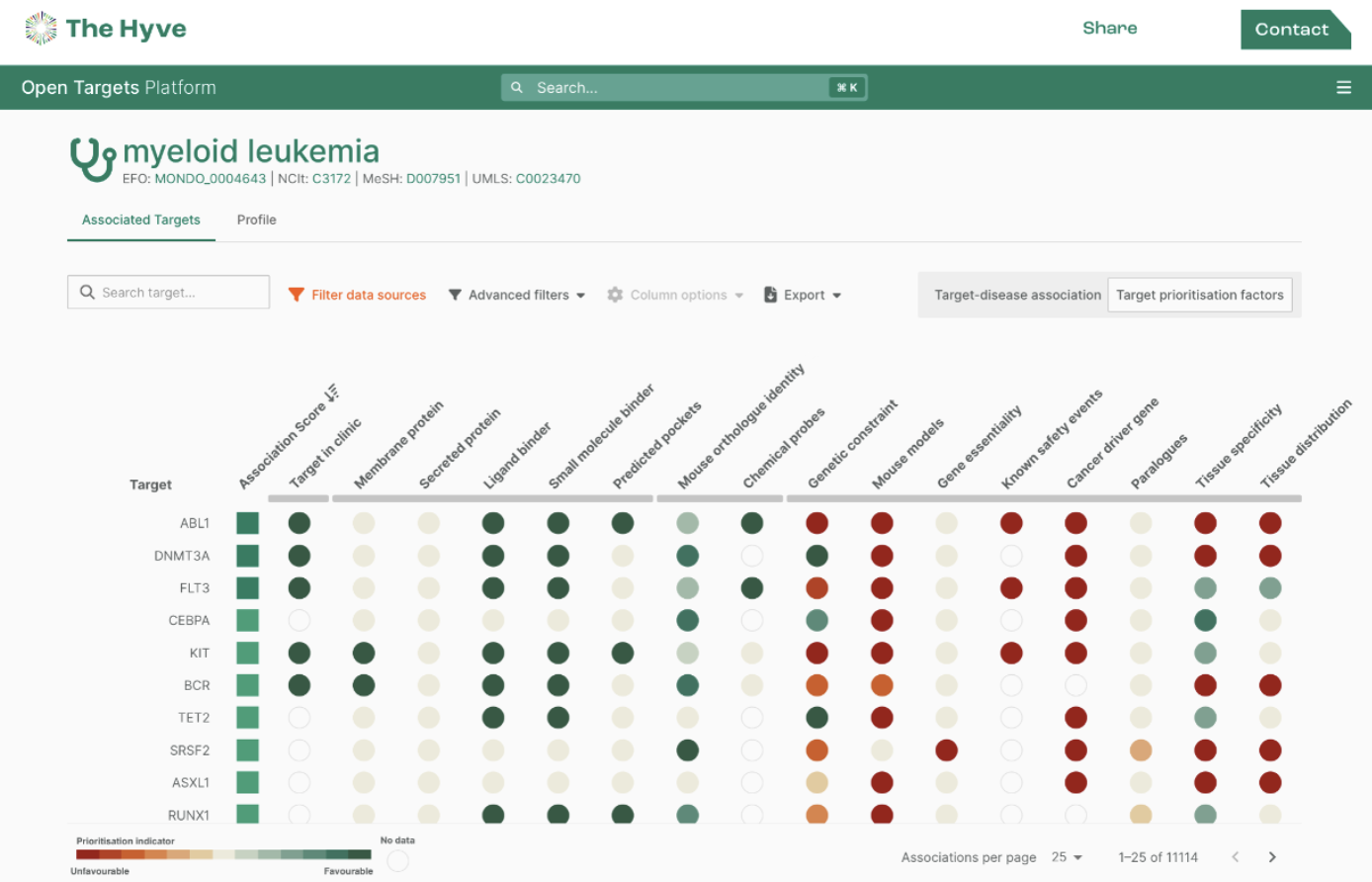
New data sources reveal additional drug target candidates, such as SERPINA1 for myeloid leukemia, as shown by the two green dots in the newly added columns and the lack of green dots elsewhere Clicking a dot opens up a detailed view of the evidence to get more information.
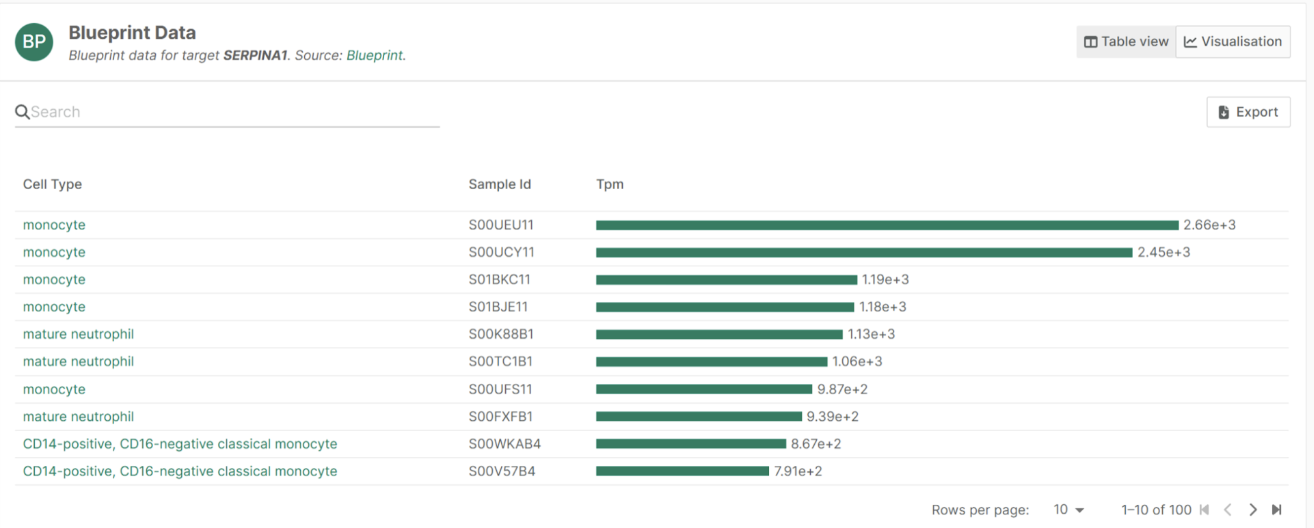
When we investigate the gene SERPINA1 in more detail by going to its profile page, we see that SERPINA1 is primarily expressed in immune cells, particularly monocytes (Figure 4). These cells are a type of myeloid leukocyte, indicating that this gene is highly expressed in the cell type from which this cancer derives.

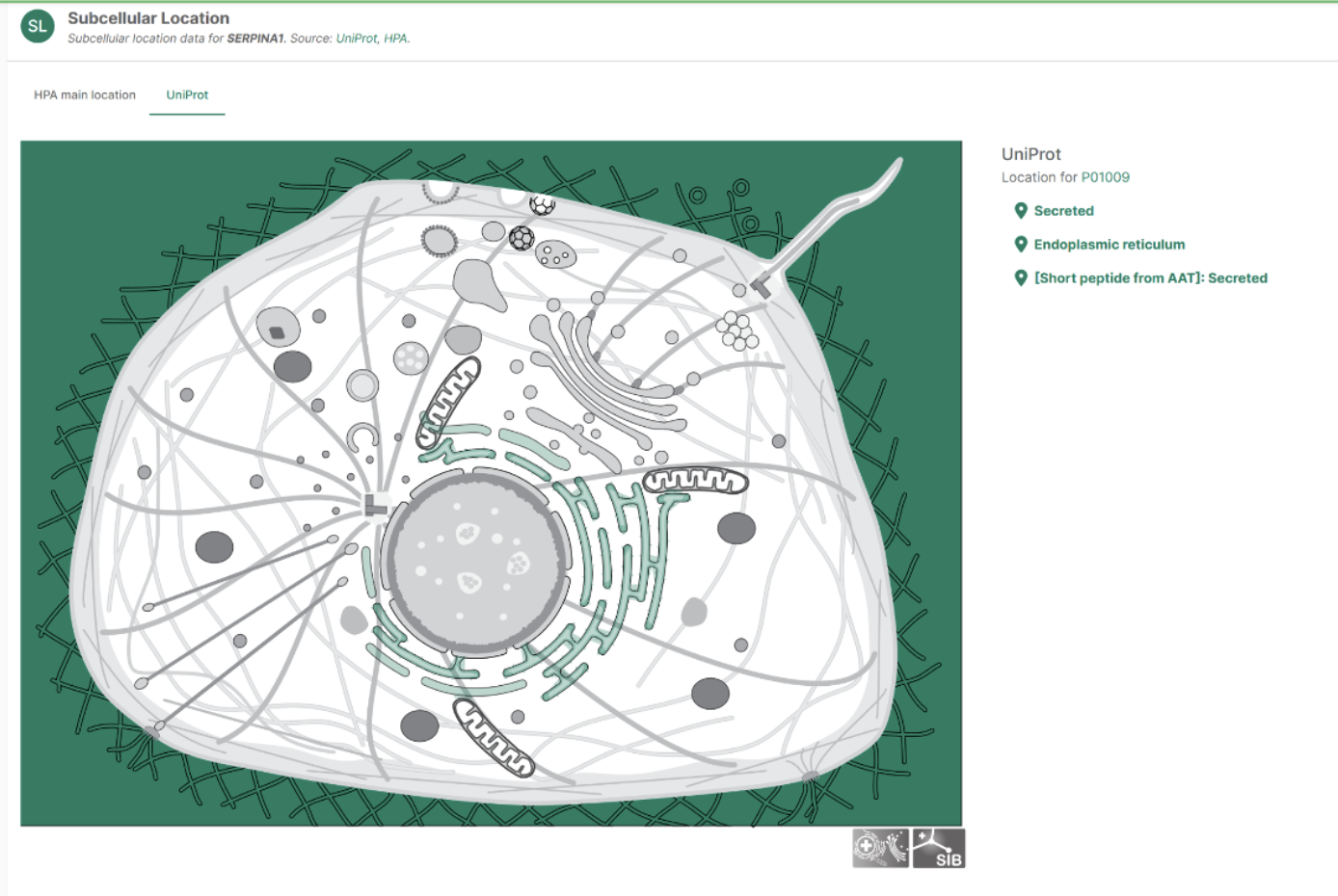
We can also examine the subcellular localization of the protein to evaluate whether it is accessible to certain classes of drugs.
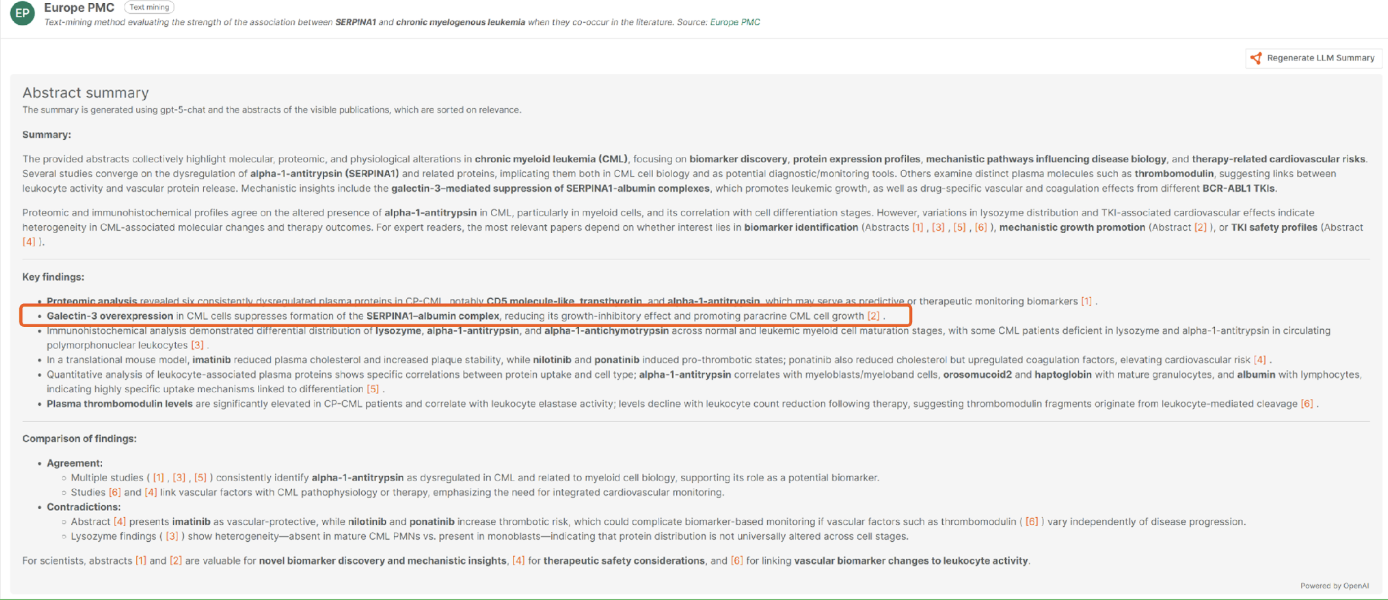
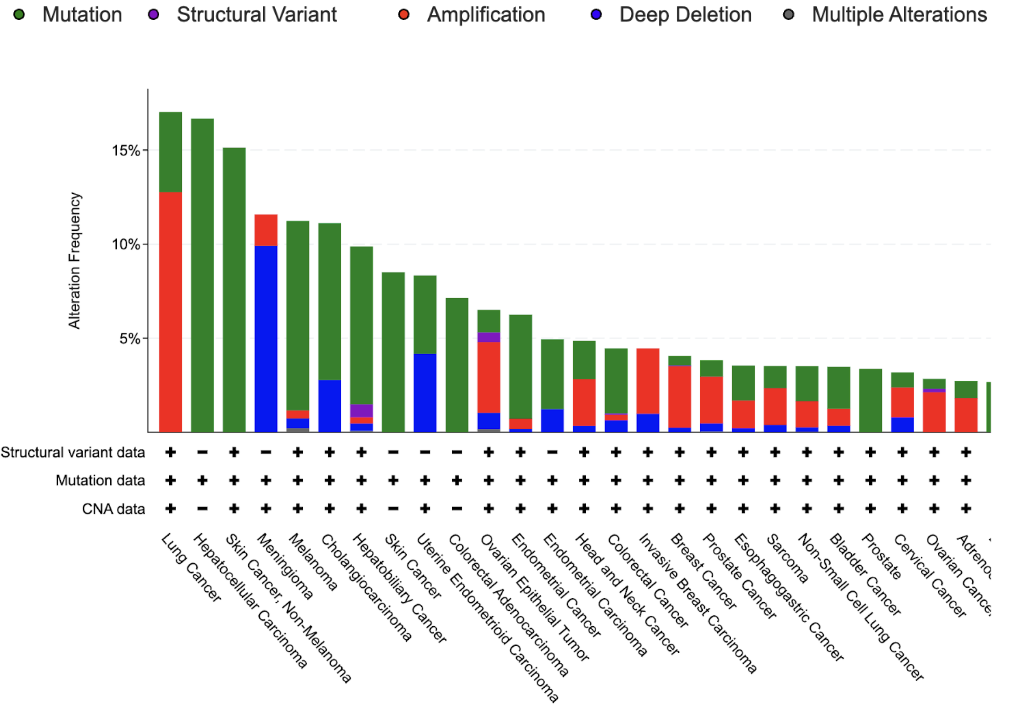
To gain more insight in previous findings on SERPINA1 and its relation to myeloid leukemia, we can go to the abstract section on the SERPINA1 evidence page. The LLM-powered abstract summarisation tool that is integrated into the Open Targets Platform [demo server] suggests that SERPINA1 may be associated with myelogenous leukemia through interactions with albumin and galectin-3 (“Suppression of SERPINA1-albumin complex formation by galectin-3 overexpression leads to paracrine growth promotion of chronic myelogenous leukemia cells”). Alterations in these genes could impact cell growth, representing potential oncogenic drivers. Follow-up analysis indicates that mutations in SERPINA1, galectin-3 (LGALS3) and albumin (ALB) occur with low frequency (~1.3%) across a wide variety of cancers and tend to co-occur (Figure 7).
Summary
The Open Targets Platform is a flexible, open-source solution for drug target discovery that allows integration of both public and custom data. In this use case, we demonstrated how adding QIAGEN OmicSoft data to the platform, and into your workflow, enables the identification of new potential drug targets, such as SERPINA1.
References
[1] Minikel EV, Painter JL, Dong CC, Nelson MR. 2024. Refining the impact of genetic evidence on clinical success. Nature. 629(8012):624-629. doi:10.1038/s41586-024-07316-0.
[2] Tsepilov YA, Suveges D, Considine D, Szyszkowski S, Ge XJ, López Santiago I, Rusina P, Alegbe T, Ho VW, Tsukanov K, et al. The Human Pleiotropic Map of GWAS Associations and Therapeutic Implications. bioRxiv [preprint]. 2026. doi:10.64898/2026.04.28.721048.