The Data Dilemma in Life Sciences
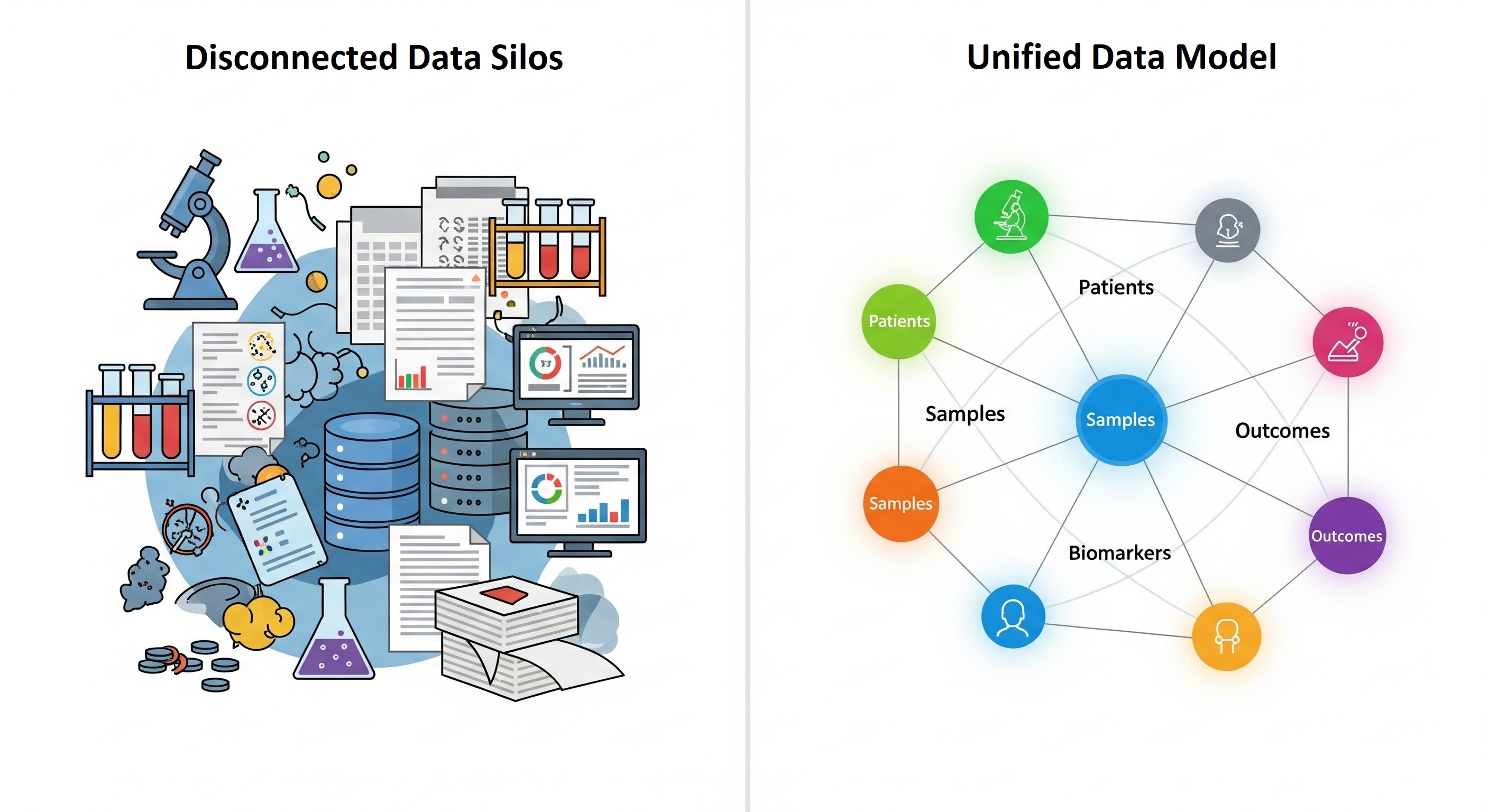
Life sciences research is not short on data; it is drowning in it. Over the past decade, the modern life sciences industry has experienced an unprecedented explosion of data, spanning genomics, proteomics, imaging, clinical trials, real-world evidence, and patient records. While this immense volume holds transformative potential for research, drug discovery, and patient care, organizations often face significant challenges: pervasive data silos, inconsistent metadata, and a general lack of a unified understanding across diverse datasets.
In pharmaceutical companies, academic research centers, and biotech startups alike, vast repositories of valuable data often remain trapped in silos, isolated databases, proprietary software, and departmental spreadsheets that are incompatible with each other. Researchers spend more time searching for data than analyzing it. Critical insights remain hidden simply because relevant datasets can’t be linked, compared, or interpreted in context.
This disorganization can result in significant financial losses for companies due to poor data quality. For example, subtle connections between datasets go unnoticed, leading to missed discoveries, and different teams collect or process the same type of data without realizing it already exists, resulting in duplicated work and a waste of time and money.
The irony is that life sciences organizations are aware of this. Ensuring that biomedical and research data are Findable, Accessible, Interoperable, and Reusable (FAIR) is now recognized as a strategic priority, not just for operational efficiency but as a competitive advantage. Yet putting FAIR into practice and adopting a FAIR data strategy is easier said than done. It demands expert knowledge of scientific domains, evolving standards, and cutting-edge computational frameworks.
This is where semantic data modeling emerges as a critical enabler. By translating complex, raw data into meaningful, integrated, and AI-ready information, semantic models provide the necessary context to harmonize disparate data sources and unlock their true value. They not only organize the chaos but also enable the creation of semantic layers and knowledge graphs that power everything from AI-driven drug discovery to large-scale translational medicine initiatives. Moreover, organizations that successfully implement semantic foundations can significantly accelerate research outcomes and enhance their decision-making capabilities, staying competitive in a rapidly evolving landscape.
In the following sections, we’ll explore what semantic data modeling really is, why it is essential for life sciences, and how it transforms the data dilemma into a strategic advantage.
What is a Semantic Model?
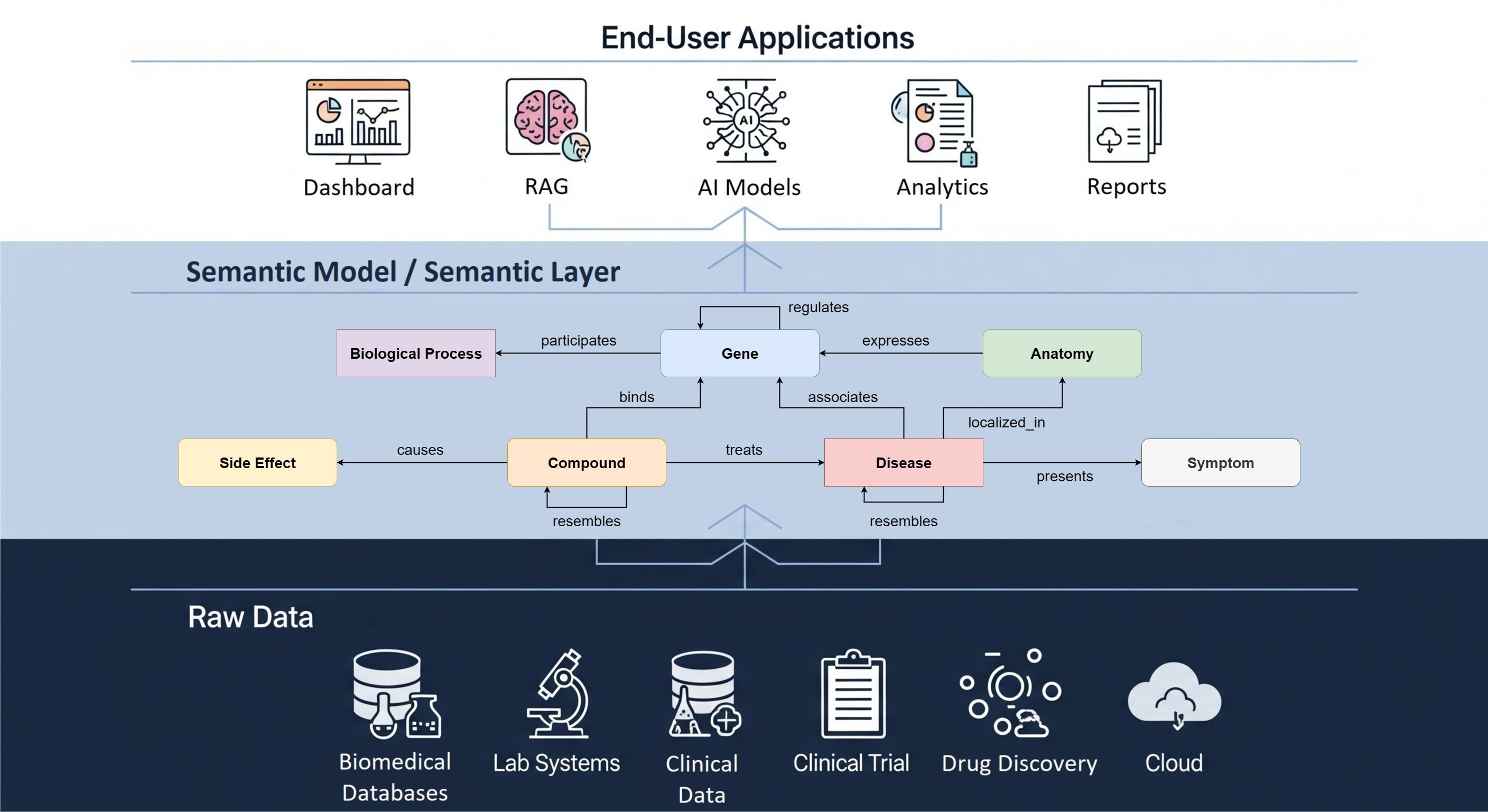
At its core, a semantic data model is about giving data meaning, not just structure. While traditional data models define how data is stored and organized in a database, semantic models translate complex technical data structures into understandable business concepts for various users within an organization. They capture the context around the data, what each term means, how entities relate to each other, and how those relationships can be understood by both humans and machines (including advanced AI systems) without requiring deep technical expertise in database schemas or SQL.
In life sciences, this is transformative. Imagine you’re working on a multi-center clinical trial, and one dataset labels a patient's condition as “hypertension” while another calls it “high blood pressure.” To a human, these are equivalent. To a computer? Without semantic alignment, they’re completely different terms. Semantic models address this issue by explicitly defining concepts and their relationships using standardized vocabularies and ontologies, thereby resolving ambiguities and ensuring that all disciplines operate from a single, consistent definition.
Key technologies like RDF, OWL, and SHACL are instrumental in realizing semantic models into machine-understandable representations. They provide frameworks to formalize business terminology, define data relationships, and enforce quality rules, ensuring consistent interpretation of concepts across diverse systems:
- RDF (Resource Description Framework): Represents data as triples (subject, predicate, object), forming the foundation of a knowledge graph.
- OWL (Web Ontology Language): Adds richer semantics, enabling precise definitions of entities and their interconnections.
- SHACL (Shapes Constraint Language): Defines rules for validating data against the semantic model.
These technologies allow data to be modeled in a machine-interpretable way, so that systems and AI algorithms can understand not just the data itself, but also the context and meaning behind it.
Semantic Model vs Semantic Layer?
While a semantic model is the formal representation of your data, a semantic layer is the operational abstraction that sits between your raw data and your analytics or AI tools. It uses the semantic model as its foundation but adds query translation, metric definition, access control, and business-friendly terminology so that scientists, analysts, and algorithms can consume the data consistently. In other words, the semantic model is the what (the structure and meaning), while the semantic layer is the how (the delivery and experience). Together, they can ensure that life sciences organizations not only agree on the definition of "patient cohort" but can also pull that cohort reliably across clinical, preclinical, and real-world datasets without reinventing logic in every tool or department.
The core components of a semantic layer are:
- Metadata service: This is the backbone, storing definitions that map technical data items (like cust_id or rev_amount_usd) to business-friendly terms ("Customer ID," "Revenue Amount in USD")
- Business glossaries, taxonomies, and ontologies: they form the semantic backbone of a semantic layer. Business glossaries establish clear, shared definitions for key terms — ensuring that “patient,” “trial,” or “sample” mean the same thing across departments. Taxonomies organize these terms into hierarchical structures, promoting consistent classification and enabling faceted search and data discovery across teams. Ontologies take this a step further by defining not just the terms and hierarchies but also the relationships between them, creating a formal, machine-readable knowledge model that powers semantic queries and AI-driven insights. Together, they ensure that data consumers have both a common language and a context-rich framework for interpreting and connecting information.
- Knowledge graph: A knowledge graph is the practical output of semantic modeling, where business concepts and their defined relationships are applied to real data and content. It represents information as interconnected nodes (entities) and edges (relationships), allowing organizations to link data across silos and surface insights based on context rather than just raw tables. In a semantic layer, knowledge graphs enable users to explore data by following relationships (e.g., tracing a drug candidate to related trials, investigators, and outcomes), turning isolated datasets into a connected, queryable web of knowledge.
Why It Matters in Life Sciences?
The life sciences sector navigates an immense data landscape, often characterized by chaos rather than coherent insights. A primary challenge is the pervasive data silos, where crucial information is fragmented across departments, diverse systems, and even different organizations. This is compounded by a lack of standardized metadata, leading to inconsistent definitions and interpretations of critical terms. Consider the following examples:
- Entity Consistency Across Domains: A “sample” should mean the same thing whether you’re in genomics, proteomics, or pathology. Without semantic consistency, misunderstandings multiply, slowing collaboration and analysis.
- Cross-Dataset Integration: Genes interact with proteins; proteins influence pathways; pathways impact disease phenotypes. Mapping these relationships requires a unified, interoperable framework.
- Compliance and Standardization: Semantic models can embed established biomedical ontologies such as SNOMED CT, MeSH, or Gene Ontology, ensuring alignment with industry standards and regulatory expectations.
To transform this chaotic data landscape into clarity, organizations are turning to semantic modeling and semantic layers. Researchers, scientists, and clinicians, while experts in their fields, may not be adept at writing complex SQL queries or navigating intricate database schemas. A semantic layer fundamentally changes this by:
- Empowering Self-Service Analytics: Non-technical users can leverage intuitive interfaces, drag-and-drop tools, or even natural language queries to explore data and create their own reports and dashboards. This democratizes data access across the organization, from lab scientists analyzing experimental results to clinical researchers reviewing patient cohorts.
- Business-Friendly Views: Technical data, often characterized by cryptic column names and complex table structures, is transformed into familiar business terms such as "patient demographics," "drug dosage," or "biomarker response". This simplification makes data immediately comprehensible and usable.
- Enhanced Discoverability: Features such as wikis, labels, and searchable catalogs within the semantic layer allow users to quickly find relevant datasets, understand their purpose, and identify points of contact for questions, dramatically reducing search time and rework.
Real-World Applications of Semantic Data Modeling in Life Sciences
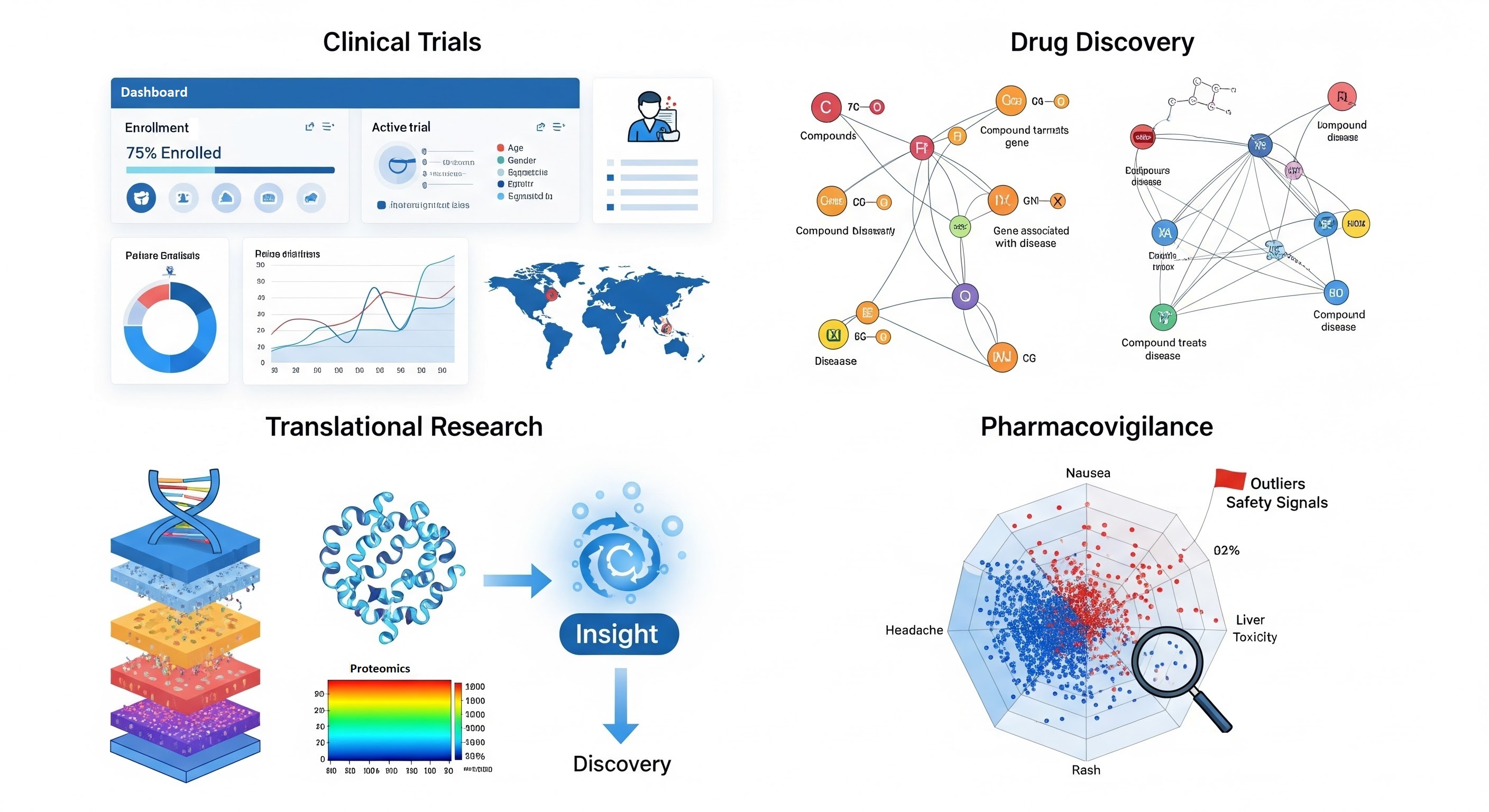
Semantic data modeling isn't just a theoretical exercise in the life sciences, it has already proven its value in speeding up research, reducing costs, and enabling discoveries that would be impossible with siloed, inconsistent data. In the following sections, we will share five real-world applications of semantic modeling in life sciences.
Accelerating Drug Discovery and Development
Pharmaceutical companies face enormous pressure to shorten the drug development lifecycle while ensuring safety and efficacy. Semantic modeling can help drug discovery by:
- Linking Preclinical and Clinical Data: A semantic model can connect in-vitro assay results with animal study outcomes and early-phase clinical trial data, creating a coherent view of a compound’s profile.
- Target Identification and Validation: Knowledge graphs derived from semantic models allow researchers to quickly identify gene-disease-drug relationships, highlighting potential therapeutic targets and reducing redundancy in experiments.
- Drug Safety: Semantic models and knowledge graphs power drug safety by unifying siloed clinical and adverse event data, enabling faster, scalable insights for vaccine development and real-time pharmacovigilance.
Example: Open Targets, an open-source platform, integrates genes, diseases, drugs, and clinical trials into the Open Targets knowledge graph, enabling researchers to prioritize targets systematically. Semantic modeling underpins the connections and ensures consistency across multiple heterogeneous datasets.
Translational Medicine and Personalized Care
Hospitals and academic medical centers can leverage semantic models to translate lab findings into patient care:
- Cohort Selection: Researchers can identify patient subgroups with specific biomarker profiles across multiple studies, even if the original datasets were stored in incompatible systems.
- Data Harmonization Across Trials: Semantic models standardize terminologies and units, enabling meta-analyses that combine data from different trials, institutions, and countries.
- Clinical Decision Support: Integrated, semantically rich knowledge graphs can feed decision-support tools, helping clinicians select the most effective therapies based on linked patient histories, molecular profiles, and trial outcomes.
Example: Academic hospitals may use semantic models to integrate LIMS, ELNs, and clinical trial management systems, creating a unified data landscape that allows translational researchers to trace insights from bench to bedside.
Enhancing Research Reproducibility and Compliance
Reproducibility is a major challenge in life sciences. Semantic modeling improves transparency and accountability by:
- Tracking Provenance: Every entity and relationship in a knowledge graph can be traced back to its source, whether it is an experimental dataset, clinical record, or literature reference.
- Standardizing Metadata: Semantic models enforce consistent labeling and classification, making it easier to replicate studies or combine results across labs.
- Regulatory Alignment: Structured, well-documented data models simplify submissions to regulatory bodies, improving compliance with standards such as FAIR and AI-ready datasets.
Knowledge Integration for Complex Biological Questions
Life sciences increasingly demand multi-domain insights: linking genomic, proteomic, metabolomic, and clinical data is essential for understanding disease mechanisms. Semantic modeling can help unlocking discoveries in many therapeutic areas by enabling:
- Cross-Domain Queries: Scientists can explore how molecular-level interactions manifest in patient outcomes without manually reconciling disparate datasets.
- Systems Biology Insights: Semantic models can capture hierarchical relationships in biological pathways, allowing simulation and modeling of complex disease processes.
Example: In systems biology projects, semantic models represent entities such as genes, proteins, and pathways, along with their interactions, providing a structured framework for knowledge graphs that support drug target discovery and mechanistic hypothesis generation.
AI and Machine Learning Enablement
Semantic data models form the backbone of AI-ready datasets in life sciences:
- Data Quality Assurance: Models define what constitutes valid, well-structured data, ensuring AI algorithms are trained on high-quality inputs.
- Feature Engineering: By explicitly modeling relationships, features derived from knowledge graphs can be more biologically meaningful.
- Explainable AI: Semantic models preserve context and provenance, making it easier to interpret AI predictions — a critical factor in regulated environments such as healthcare and drug development.
In essence, semantic data modeling transforms the fragmented landscape of biomedical data into a coherent, actionable knowledge network. From accelerating drug discovery to enabling personalized medicine, improving reproducibility, and supporting AI-driven insights, its applications touch every stage of the life sciences pipeline.
Building Blocks: From Semantic Models to AI-Ready Knowledge Graphs
Creating AI-ready knowledge graphs in life sciences is not a single-step task. It is a structured lifecycle, that combines data engineering, semantic modeling, and visualization. This section breaks down the lifecycle step-by-step and highlights the key tool categories that make it possible.
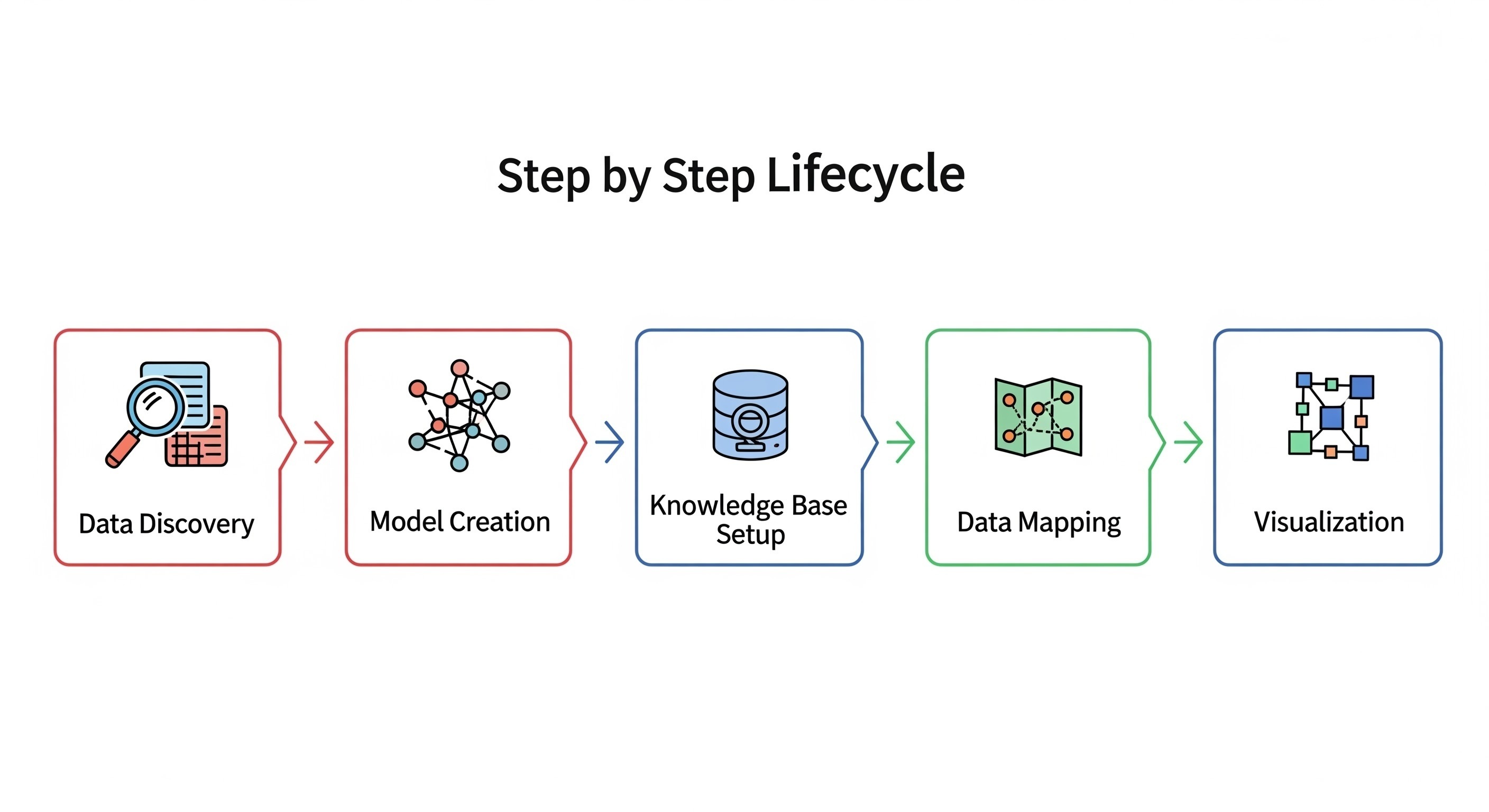
Data Discovery & Inventory
The first step in building a knowledge graph is understanding your data landscape. Life sciences organizations often deal with heterogeneous datasets: clinical trials, lab experiments, omics data, and literature-derived knowledge. Data landscaping involves meticulously mapping and organizing existing data sources within an organization.
Purpose: Identify entities, relationships, and data quality at scale.
Process: Scan datasets, fingerprint sources, and collect basic statistics such as row counts and entity frequencies.
Outcome: A structured data inventory that provides a clear picture of available information and gaps.
Open Source Tools:
Amundsen: A metadata-driven discovery platform.
DataHub: Originally created at LinkedIn, DataHub is a modern metadata platform for data discovery, lineage, and governance.
OpenMetadata: A unified metadata and governance platform that provides data discovery, lineage, quality, and collaboration capabilities.
OHDSI White Rabbit: For clinical and healthcare datasets.
Model Creation & Repository
Once the data is understood, you define a semantic model that represents the domain knowledge: entities (genes, proteins, compounds), relationships (interacts_with, inhibits), and attributes (expression levels, dosage).
Purpose: Create a blueprint that unifies all datasets under a common semantic structure.
Process: Use a repository to manage multiple semantic models, apply constraints, and version your definitions.
Outcome: A robust semantic model that ensures consistency and interoperability.Open Source Tools:
WebProtege: Collaborative ontology modeling and management.
SHACL Shapes Libraries: Define validation rules and constraints to enforce data integrity.
LinkML: A framework for building interoperable data models using YAML that can be compiled into JSON Schema, RDF, SQL, and more for semantic data exchange.
ROBOT: A command-line tool for automating ontology workflows, including reasoning, merging, extracting, and validating OWL ontologies.
Knowledge Base Setup
The semantic model is operationalized by creating a knowledge graph, which stores the interconnected data in a way that supports queries and analysis.
Purpose: Provide a persistent, structured storage for entities and relationships.
Process: Choose between triple stores or graph databases depending on your scale and use cases.
Outcome: A fully navigable knowledge graph that integrates data across multiple sources.Open Source and Commercial Tools:
Jena, RDF4J, OpenLink Virtuoso, GraphDB: Triple stores optimized for Linked Data.
Neo4J: Popular graph database for labelled property graphs (LPG).
Data Mapping
With the knowledge graph in place, raw datasets are aligned with the semantic model to populate the graph with instances and relationships.
Purpose: Ensure data conforms to the model and can be queried reliably.
Process: Annotate raw data with entity and relationships, validate against SHACL constraints, and track provenance.
Outcome: A validated knowledge graph where all nodes and edges adhere to the semantic model.
Tools:ETL frameworks or custom data pipelines can be used here, often combined with semantic validation.
Visualization & Exploration
Finally, the knowledge graph is made actionable through visualization and exploration tools, which help researchers uncover insights and make data-driven decisions.
Purpose: Translate complex relationships into intuitive, interactive views for analysis and decision support.
Process: Generate network diagrams, nested bubble plots, or layered visualizations that highlight key connections and patterns.
Outcome: Stakeholders can explore, query, and interpret data without needing deep technical expertise.Open Source and Commercial Tools:
Gephi: Network analysis and graph visualization platform.
Cytoscape: Particularly useful for biological networks.
ReGraph: For interactive, web-based graph visualization.
Neo4J Browser: Neo4J graph query and visualization interface.
AI-Ready Outputs
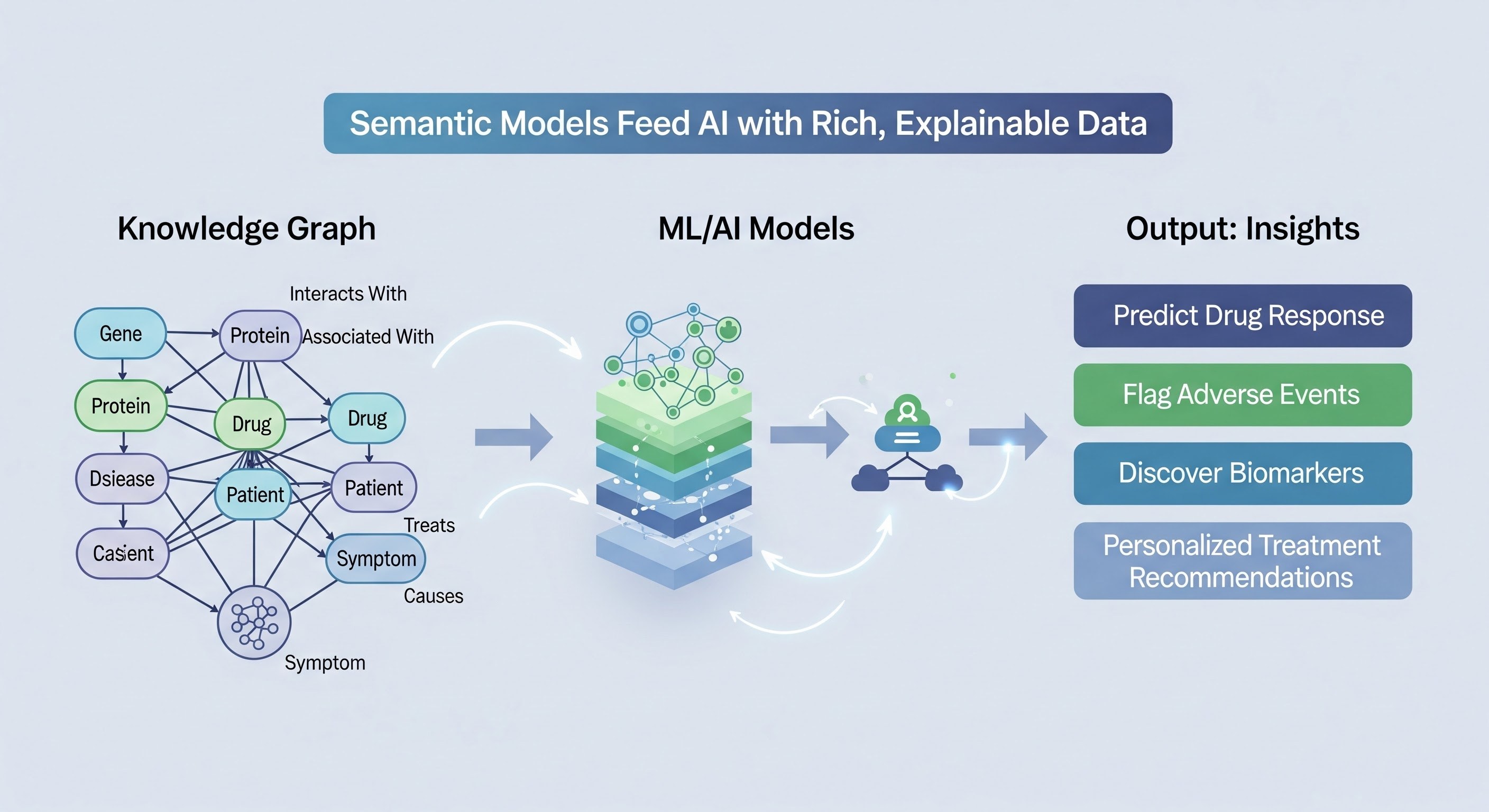
Once a semantic model has been fully operationalized into a validated, visualizable knowledge graph, it transitions into an AI-ready asset. In the life sciences domain, this transformation is crucial because predictive modeling, translational research, and drug discovery all demand structured, high-quality data that is not only machine-readable but also semantically interpretable.
Rich Feature Sets for Predictive Modeling
Each node (entity) and edge (relationship) in a semantic knowledge graph carries attributes and metadata that can serve as features for AI and machine learning models. For instance:
- Nodes representing genes may include expression levels, mutation status, or pathway involvement.
- Edges representing interactions can encode type, strength, and confidence levels of relationships.
- Experimental provenance, temporal context, and tissue specificity can all be preserved as structured attributes.
By embedding such rich, semantically contextualized features, AI models are no longer operating on raw, disconnected data—they are leveraging a highly interconnected network that mirrors real-world biological systems. This drastically improves the predictive power and relevance of AI applications in drug discovery, biomarker identification, and clinical decision support.
Explainability Through Semantic Context
One of the biggest challenges in life sciences AI is explainability. Unlike black-box models that output predictions without rationale, AI models built on semantic knowledge graphs can trace predictions back to explicit relationships and underlying experimental evidence.
- A predicted drug-target interaction can be traced to supporting protein-protein interactions, gene expression correlations, or literature citations encoded in the graph.
- Adverse event predictions can be linked to known pharmacological pathways, off-target interactions, or prior clinical trial data.
This traceability of reasoning is essential for regulatory compliance, scientific validation, and adoption by clinicians and researchers. Semantic data modeling, therefore, bridges the gap between advanced AI capabilities and practical, interpretable insights.
Iterative Learning and Continuous Updates
Knowledge graphs are inherently iterative and extensible. New experimental results, clinical trial outcomes, literature discoveries, or omics datasets can be continuously ingested, mapped to the existing semantic model, and validated. This iterative process enables:
- Continuous improvement of AI model accuracy over time.
- Rapid incorporation of new scientific knowledge without rebuilding models from scratch.
- Flexible adaptation to emerging research questions or therapeutic areas.
In essence, a semantic knowledge graph is a living model of biomedical knowledge, capable of evolving alongside science itself.
Example: Multi-Omics Drug Discovery
Consider a knowledge graph that integrates genomics, proteomics, metabolomics, and clinical trial data. This AI-ready graph can:
- Feed features into a machine learning model to predict drug efficacy across patient subpopulations.
- Highlight potential adverse events by mapping molecular interactions to clinical outcomes.
- Provide explanations for predictions via explicit biological relationships and pathway context.
Here, every prediction is grounded in biology, enhancing trust, interpretability, and translational impact.
Challenges and Best Practices for Implementing Semantic Data Modeling
Implementing semantic data modeling in the life sciences is a transformative but complex endeavor. Even with modern tools and frameworks, organizations face practical and organizational challenges that must be navigated carefully to ensure success.
Key Challenges
Stakeholder Alignment Across Departments
Life sciences organizations often consist of multiple departments (research, clinical, regulatory, IT, and data science), each with its own priorities, vocabularies, and data practices. Achieving alignment requires:
- Clear articulation of project goals and benefits for each stakeholder group.
- Early identification of potential conflicts or gaps in domain knowledge.
- Establishing communication channels to coordinate decisions on data modeling standards, entity definitions, and semantic relationships.
Without this alignment, semantic models risk fragmentation or lack of adoption, undermining the value of knowledge graphs.
Incremental vs Big-Bang Implementation
Building an enterprise-wide knowledge graph or semantic layer is rarely feasible as a single, large-scale initiative. Attempting a “big-bang” implementation can lead to:
- Delays due to complex data integration issues.
- Model misalignment with evolving scientific understanding.
- High risk of stakeholder fatigue and project abandonment.
Instead, adopting incremental, phased approaches allows teams to validate models early, gather feedback, and iterate effectively.
Continuous Model Evolution
Biomedical knowledge evolves rapidly, and semantic models must keep pace. Challenges include:
- Integrating new experimental data, clinical trial results, and literature.
- Updating entity definitions and relationships without breaking existing applications.
- Ensuring backward compatibility for AI models and analytics pipelines.
This requires a robust strategy for ongoing governance, versioning, and change management.
Best Practices
Start Small, Scale in Phases
Begin with a well-defined knowledge domain (e.g., a single pathway, disease area, or subset of clinical trials). Early success in a limited scope builds confidence, generates learnings for scaling, and helps justify further investment.
Involve Domain Experts Early
Semantic modeling is only as accurate as the domain knowledge it encodes. Engage biologists, clinicians, pharmacologists, and other subject matter experts from the outset to:
- Define entities, relationships, and attributes correctly.
- Identify meaningful hierarchies and ontologies.
- Validate early iterations of the model before integration with larger datasets.
Maintain a Living Ontology
Treat your semantic model as dynamic rather than static. Regularly update the ontology with new discoveries, clinical findings, and regulatory changes. Tools like SHACL shape libraries or WebProtege can help manage versioning and enforce validation rules as the model evolves.
Align With Existing Data Governance Frameworks
Semantic data modeling should complement, not replace, existing governance structures. Align your modeling practices with policies on:
- Data quality and provenance.
- Security, privacy, and compliance (HIPAA, GDPR).
- Metadata standards and documentation.
By acknowledging these challenges and adhering to best practices, life sciences organizations can maximize the impact of semantic data modeling, creating AI-ready knowledge assets that drive discovery, efficiency, and innovation.