Decentralization has become a growing trend especially with the advent of technologies such as Blockchain. It provides the key benefits of data and infrastructure being shared and distributed, while centralization enables more authority and control. The choice between being centralized and decentralized infrastructure is difficult and very contextual. In reality, businesses rarely commit to one of these models and you will see a mix of both infrastructures in an enterprise environment. And if connected accurately together, they provide substantial benefits. We refer to it as a hybrid approach. Additionally, adherence to the FAIR guiding principles (making digital assets Findable, Accessible, Interoperable, Re-usable) can help to ensure that data infrastructures reflect the FAIR requirements of different research disciplines. Understanding the infrastructure models will help determine the degree to which your organization should centralize, decentralize or go with a hybrid approach. Let's dive into the merits and demerits of these infrastructure models.
Merits and Demerits of Centralized, Decentralized and Hybrid Infrastructures
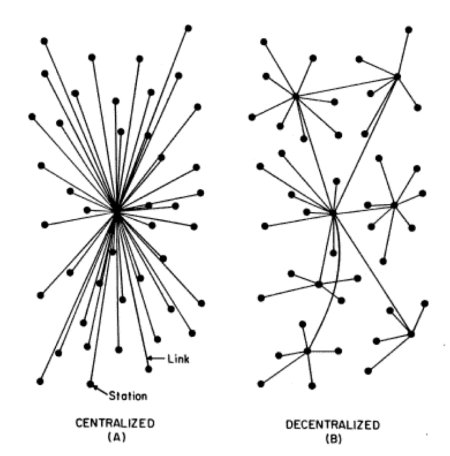
A Centralized infrastructure involves a formal authority who standardizes and plans the IT activities. This is a more traditional approach that works best for enterprises that require greater network control and deploy a vertical style of coordination. One advantage of this approach is that it provides a more consistent process, yielding consistent outcomes, less expenditure on training and resources and much easier and quicker reporting. Decision making and change management in a centralized infrastructure are quite straightforward with smooth, continuous improvements in short feedback loops.
A classic scenario for a centralized IT infrastructure is an ETL (Extract Transform Load) team extracting and transforming data from multiple sources and loading them into a destination system. Application developers and data engineers can then build applications leveraging the structured data from these central systems. This also enables the end users such as business executives and data scientists alike to use the structured data for visual analytics and business intelligence (BI) tasks. Overall, this approach reduces high data variability by providing consistency and operational resilience to make the informed decisions.
A modern paradigm of a centralized infrastructure is the building of a data lake which harbors raw and unstructured data. The purpose of the data in this data lake may not have been determined yet, but this approach reduces the overhead on pre-structuring data as it can be ingested in a raw format. Several data warehouses can be built on top of a data lake, using the necessary ETL-pipelines to create structured data. Several teams, such as ingestion, data engineering and bioinformatics teams, can push data from several sources such as hard drives, databases and data catalogs to ingest raw and unstructured data into an Enterprise data lake. This process is supported by core IT enterprise infrastructure in the form of APIs, ingestion pipelines, self-service portals which can be cloud-native and/or on-premise infrastructure. The centralized model is quite common to most enterprises. It provides more control, less overhead and less expenditure in training resources.
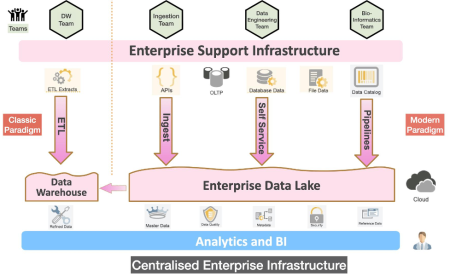
Data lakes have been popular in the healthcare industry as it allows for a combination of structured and unstructured data. After defining the analysis purpose, the relevant data can be extracted and compiled with a common data model (CDM) such as OMOP (Observational Medical Outcomes Partnership). A CDM aims at bringing together disparate observational databases to allow for a common or standardized analysis without the need to worry about preparing data which might be located in several environments such as company-to-company or different hospitals.
A decentralized infrastructure is where every department has autonomy. The benefit of this approach is that there is no single point of failure; every department has some sort of internal infrastructure to handle, analyze and manage data. Thus they are not reliant on a single central server to handle all the processes. It also implies that there is no central control and if departments have to interact with each other, the data must be standardized to the tools used by other departments. For a large enterprise, such as pharmaceutical companies and hospitals, this can work initially. But with growing data and software needs, a central body must be created, otherwise too much time will be spent on data inventory, landscaping and compliance. So, within a decentralized infrastructure, a variation of a centralized infrastructure exists for every department or division.
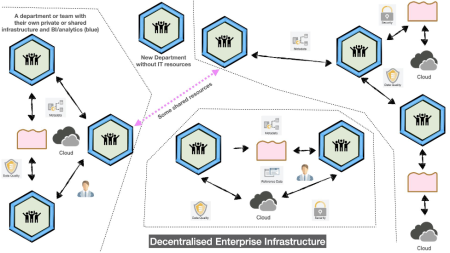
At The Hyve, we hold the view that a hybrid approach works best for large enterprises. In this case, there is a central body such as a Chief Data Office (CDO) mainly linked to the Enterprise IT. It is responsible for enterprise-wide governance and utilization of information as an asset and laying foundations for identifier schemes, unified domain model (UDM), metadata and provenance standards along with catalog function and enabling central registries. These standards and guidelines are then implemented company wide, as shown in the illustration below.
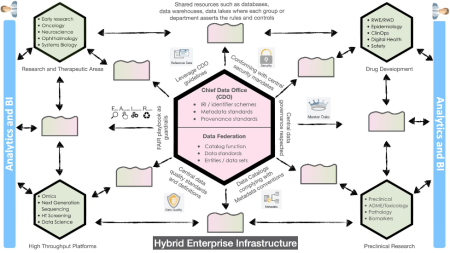
While in this scenario each department can deploy their own data catalog, the digital assets are registered in a central registry maintained by the CDO. An example of such a central registry is COLID, an open-source corporate linked data tool developed by Bayer Pharmaceuticals. It is used to register and manage corporate data assets in an RDF-linked graph format where the assets are handled and stored locally by departments. The interconnectivity between the data assets and the systems operating on it, can be represented by tools such as dashboards, static and dynamic plots and knowledge graphs.
The hybrid approach has been adopted by a number of pharmaceutical companies. In his presentation at BioIT 2020, The Hyve founder Kees van Bochove discussed the advantages of a hybrid infrastructure in an enterprise setting. Please watch it here:
Let's start collaborating
If you think a hybrid approach, or some aspects of it, could benefit your business and improve FAIR data management within your organisation, please do not hesitate to get in touch with The Hyve.
Our experts will gladly help you with integrating FAIR − at any level − in your company.


