The Challenge
The main goal of this project was to implement the FAIR principles to create fully AI-ready data for a global top 10 pharmaceutical company. One of the biggest challenges here is to make the data not only machine-readable but also machine-actionable.
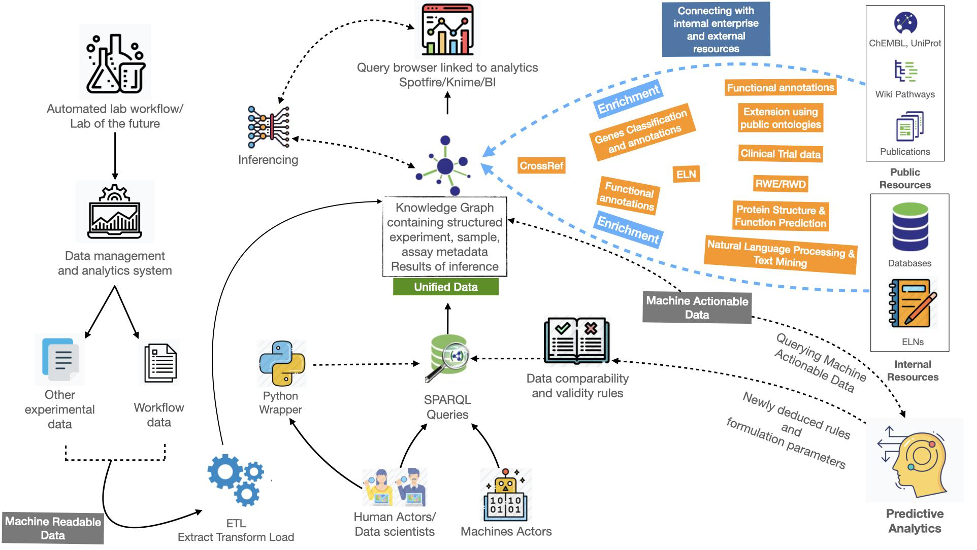
Lab automation processes, implemented in recent years, led to an increased generation of data. Combining this data with other types of in-house and public data to enable processing by relevant AI applications requires a data standardization concept, such as the FAIR principles.
Therefore, together with our customer’s data experts, we created a specific proof of concept to illustrate how high performance liquid chromatography (HPLC) data can be used for predictive formulation development leveraging AI, the FAIR principles, and knowledge graph technologies.
How we addressed this
With this project, we demonstrated that the FAIR principles can be implemented to achieve machine actionability. This was done by transforming a liquid antibody formulation dataset (machine-readable) into a FAIR data asset (machine-actionable). This resulted in a knowledge graph that contains the experimental data as well as relevant metadata.
This graph was subsequently used to demonstrate two user scenarios:
establishing the experimental validity and comparability of datasets,
finding datasets that match certain criteria.
The user could be either a machine actor or a human actor practicing data science, for example by designing and building machine learning (ML) algorithms that leverage the FAIR data assets.
Once the data is conformed to a consistent knowledge representation structure, using for example public ontologies as mentioned below, input to ML algorithms can easily be standardized. This is achieved using queries on the standardized knowledge representation.
Several modular steps are required to achieve standardization.
- A semantic model representing the core elements: experimental design, assay, sample, measurements, and derived values need to be identified (if present) or created. These metadata elements are ideally conformed to public ontologies such as BFO (Basic Formal Ontology), OBI (Ontology for Biomedical Investigations), or IAO (Information Artefact Ontology).
- This semantic model is subsequently used as a blueprint for a knowledge graph, which is populated using analytical data − in this case the liquid antibody formulation dataset.
- An experimental validation table serves as a set of rules for testing data comparability. These rules are also modeled within the knowledge graph and can later be queried as SPARQL queries.
- After testing the comparability, additional metadata elements concerning measurements and derived values can be added for testing the ML learning model on/for predictive analysis. This modeling approach is an iterative process that keeps running until the full analytical data comparability is achieved and the input to the ML learning model is fully optimized.

The Outcome
With our knowledge graph strategy, we were able to demonstrate the two user scenarios described above. The scenarios support our customer’s biologics pipeline with analytical data for liquid formulation in a secure process that follows data integrity, validity, and data quality rules.
We choose a semantic approach as it allows for the data to be:
- connected across experiments
- structured with standardized metadata elements leveraging public FAIR ontologies
- unambiguous and readily available for digestion by humans and machine actors
- queryable using data validity rules to establish comparability
- represented visually in a knowledge graph as connected data
- integrated with internal and external resources for further enrichment
- inferenced enabling the automated discovery of new facts based on a combination of data and rules
Furthermore, the growing data volume within the knowledge graph, as it is aligned with public FAIR ontologies and written explicitly in Resource Description Framework (RDF) and thus machine actionable, can be used directly for machine learning algorithms and further process optimization. This approach allows for data from several groups and sites to be ingested into one knowledge graph and allows for establishing data comparability at a global level.
If the measurements are encoded in a standardized way and key metadata elements are systematically specified for the experiments, one can automate much of the data processing and feature extraction which is an iterative and time-consuming process in machine learning.
However, one key requirement is that the datasets are annotated with structured metadata by design since retroactively FAIRifying data and applying this structure is very costly and hard to scale in the long run. In an ideal scenario, FAIR-by-design rather than FAIRifying wins and saves time, money, and resources. The model we used in this case gives a good starting point for implementing structured metadata by design and is compatible with lab automation.
Read more about how the FAIR guidelines can facilitate machine learning.